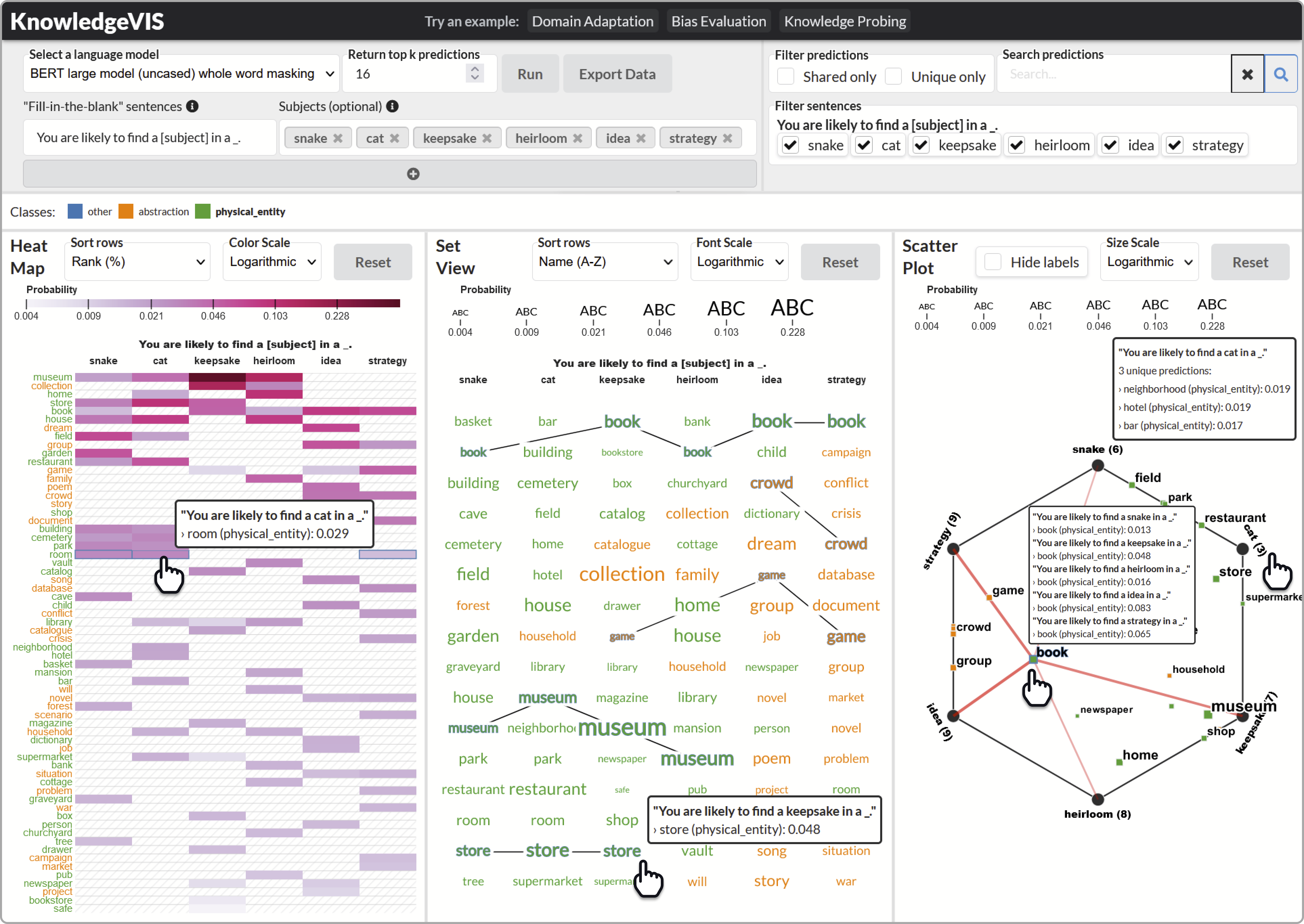
Recent growth in the popularity of large language models has led to their increased usage for summarizing, predicting, and generating text, making it vital to help researchers and engineers understand how and why they work. We present KnowledgeVis, a human-in-the-loop visual analytics system for interpreting language models using fill-in-the-blank sentences as prompts. By comparing predictions between sentences, KnowledgeVis reveals learned associations that intuitively connect what language models learn during training to natural language tasks downstream, helping users create and test multiple prompt variations, analyze predicted words using a novel semantic clustering technique, and discover insights using interactive visualizations. Collectively, these visualizations help users identify the likelihood and uniqueness of individual predictions, compare sets of predictions between prompts, and summarize patterns and relationships between predictions across all prompts. We demonstrate the capabilities of KnowledgeVis with feedback from six NLP experts as well as three different use cases: (1) probing biomedical knowledge in two domain-adapted models; and (2) evaluating harmful identity stereotypes and (3) discovering facts and relationships between three general-purpose models.
@article{Coscia:2023:KnowledgeVIS,
author={Coscia, Adam and Endert, Alex},
journal={IEEE Transactions on Visualization and Computer Graphics},
title={KnowledgeVIS: Interpreting Language Models by Comparing Fill-in-the-Blank Prompts},
year={2023},
volume={},
number={},
pages={1-13},
doi={10.1109/TVCG.2023.3346713}
}